
La Historia del Reconocimiento Óptico de Caracteres (OCR)
A menos que no hayas estado siguiendo nuestro blog, ahora deberías tener una comprensión clara de qué es la tecnología de Reconocimiento Óptico de Caracteres (OCR) y cómo funciona. Sin embargo, ¿cuánto sabes sobre su historia? ¿Puedes adivinar cuánto tiempo lleva existiendo? ¿Crees que es más antigua que la World Wide Web? ¿Y qué hay de la PC? A continuación, responderemos todas tus preguntas.
Sí, la tecnología OCR ha existido más tiempo que la Web y la PC
Aunque la World Wide Web fue inventada en 1989 —por el científico británico Tim Berners-Lee mientras trabajaba en CERN— y, según el Museo de la Historia de la Computación, la primera PC —la Kenbak-1— se lanzó en 1971, la tecnología OCR se remonta a principios del siglo XX.
Sentando las bases (1914-1950s)
- 1914: En 1914, el físico Emanuel Goldberg inventó una máquina capaz de leer caracteres y convertirlos en código telegráfico. Se considera uno de los primeros ejemplos de tecnología OCR.
- 1931: Más tarde, Goldberg desarrolló lo que llamó una “Máquina Estadística”, una máquina electromecánica para buscar archivos en microfilm utilizando un sistema de reconocimiento óptico de códigos.
- 1950s: David H. Shepard trabajaba como criptólogo en la Agencia de Seguridad de las Fuerzas Armadas (AFSA), ahora la Agencia de Seguridad Nacional (NSA) de EE.UU., cuando en 1951 desarrolló “Gismo” en su tiempo libre. Construida en un ático junto a su colega Harvey Cook Jr., “Gismo” era una máquina capaz de leer las 26 letras del alfabeto producidas por una máquina de escribir estándar. En 1952, Shepard fundó su empresa, Intelligent Machines Research Co. (IMR). En el video a continuación, puedes ver un episodio de 1959 del programa de concursos de EE.UU. “I’ve Got a Secret”, en el que David H. Shepard aparece con el secreto “Inventé una máquina que lee y escribe”.
Click aqui para aceptar las cookies y ver el video.
Primeras aplicaciones comerciales (1950s-1960s)
- 1954: La revista Reader’s Digest de EE.UU. se convirtió en la primera empresa en instalar un lector OCR en su oficina en 1954. Se usaba para convertir informes de ventas mecanografiados en tarjetas perforadas. Otras empresas pronto siguieron su ejemplo.
- 1959: IBM desarrolló la máquina OCR IBM 1287, destacada por ser el primer escáner comercialmente vendido capaz de leer números escritos a mano.
- 1960s: Ray Kurzweil, quien se convertiría en una figura clave en la historia del OCR, comenzó a investigar tecnologías de reconocimiento de patrones en la escuela secundaria. En 1965, ganó el primer premio en la Feria Internacional de Ciencia con un software de reconocimiento de patrones que analizaba obras de música clásica y creaba composiciones en el estilo de un compositor dado.
El nacimiento de Kurzweil Computer Products y la digitalización de bibliotecas (1970s-1980s)
- 1974: Ray Kurzweil fundó Kurzweil Computer Products, Inc. y desarrolló el primer sistema de reconocimiento óptico de caracteres de fuente universal, capaz de reconocer texto en cualquier fuente normal.
- 1980s: En 1980, Ray Kurzweil vendió Kurzweil Computer Products, Inc. a Xerox, que lo renombró como Scansoft.
- 1980s: Durante esta década, la tecnología OCR se utilizó ampliamente para digitalizar documentos impresos, especialmente en bibliotecas y oficinas.

OCR digital y la era de la informática personal (1990s-2000s)
- 1990s: Caere Corporation introdujo OmniPage, uno de los primeros programas OCR para PC.
- 1999: ABBYY lanzó FineReader, un software OCR de alta precisión para múltiples idiomas.
OCR con IA y soluciones en la nube (2010s-2020s)
- 2015: Se funda Incode Technologies por Ricardo Amper.
- 2018: Google lanzó Tesseract 4.0, incorporando redes neuronales para mejorar el reconocimiento de texto escrito a mano.
- 2020s: El OCR se integra en servicios en la nube y aplicaciones impulsadas por IA.
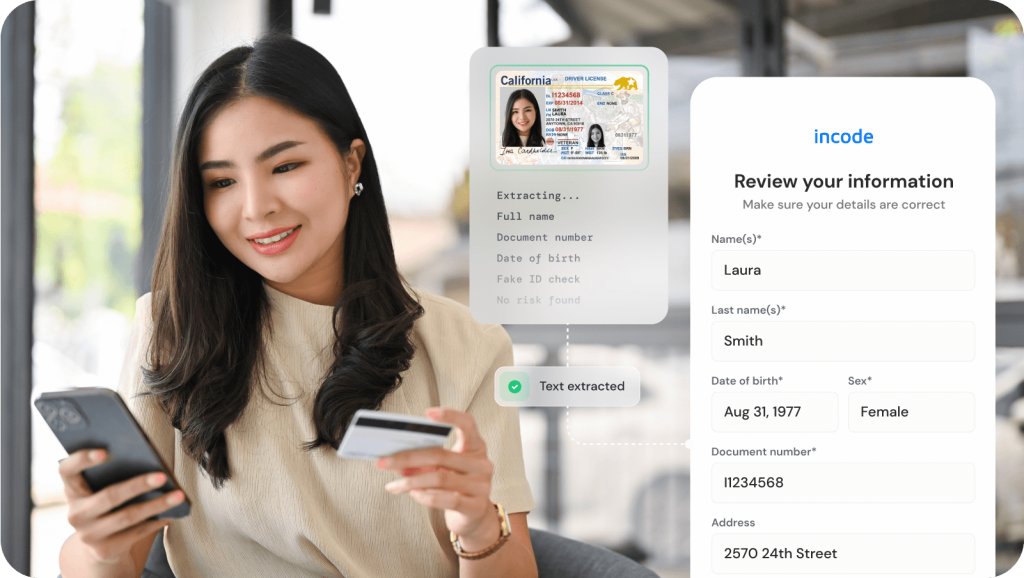
Incode lanza su tecnología OCR
- 2023: Incode lanza su tecnología OCR para verificación de identidad, capaz de extraer datos de más de 4900 documentos de identidad con una precisión casi perfecta.
Descubre más sobre la tecnología OCR de Incode.